高性能 GPU 并行计算¶
庞龙刚@华中师范大学
学习内容¶
- 什么是并行计算
- GPU 并行计算的优势及软硬件平台
- GPU 并行计算的几种方法
- 底层 Cuda,OpenCL
- 高层 OpenACC,PyOpenCL
- 新的 GPU 并行编程范式
- Tensorflow,Pytorch,JAX,Numba
- 其他并行计算方法
什么是并行计算(Parallel Computing)¶
并行计算是与串行计算对立的概念。
比如,一个很大的 for 循环,
long nmax = long(1.0E12);
for (long i = 0; i < nmax; i++) {
a[i] = b[i] + c[i];
}
传统的串行计算需要从第一个元素开始,遍历到最后一个元素。
而并行计算可以将 for 循环分成多个独立的区间,将每个区间上的计算任务分配到不同的 CPU 或 GPU 上,同时进行计算,减少总计算时间。
并行计算带来科研优势 (Parallel Supremacy)¶
谷歌曾提出概念“Quantum Supremacy”(量子霸权或量子领先优势):如果量子计算机研制方面发生突破,则很多加密算法,很多不能求解的量子多体问题都迎刃而解。
同理可以提出概念“Parallel Supremacy”(并行计算霸权):如果你的程序可以比别人快 100 或 1000 倍,那么就能建立科研上的巨大优势。
- 100 天的计算量可以 1 天,或 1 小时内完成
- 同样的时间内,可以比别人多尝试几百个参数组合 (贝叶斯分析)
- 可以为机器学习快速积累大量数据(大数据生成)
- 可以训练更强大的深度神经网络,如 AlphaFold,FermiNet 等 (人工智能与科学计算的交叉)
高性能并行计算的分类¶
- 单节点共享内存(显存)编程 .vs. 多节点通信(MPI)
- CPU(中央处理单元).vs. GPU(图形处理单元)
- 数据并行(SIMD) .vs. 指令并行
我们今天重点介绍单节点共享内存(显存)、数据并行的GPU编程。一些名词的定义如下,
- MPI: Message Passing Interface
- CPU: Central Processing Unit
- GPU: Graphics Processing Unit
- SIMD: Single Instruction Multi Data
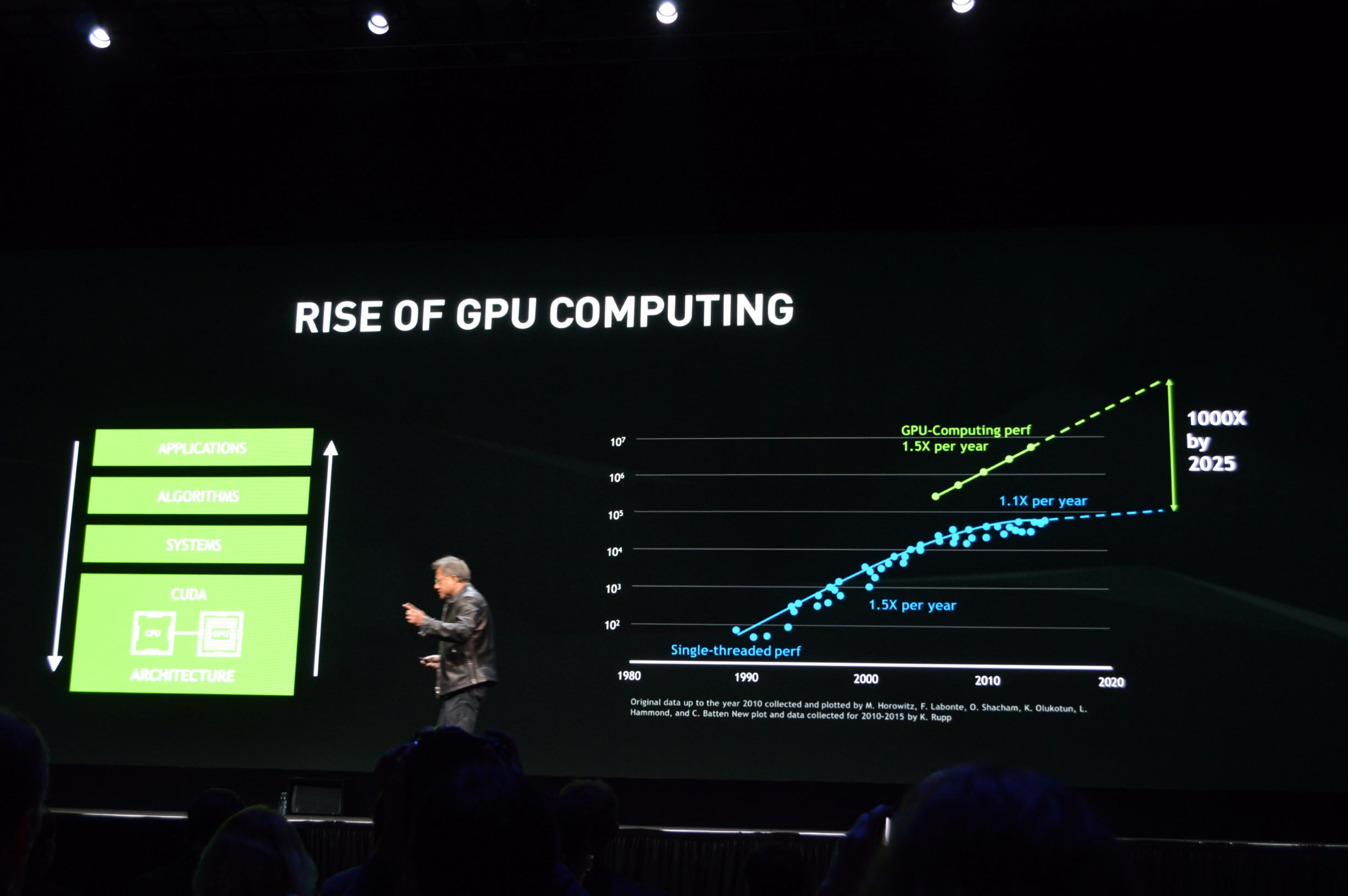
GPU 并行计算的崛起¶
摩尔定律:芯片上晶体管数量每 18 个月增加 1.5 倍,性能也提升约 1.5 倍 (但 CPU 上的摩尔定律正在失效,增长曲线出现平台结构)
NVIDIA(英伟达)CEO黄仁勋指出:从2015到2025年,GPU 的性能增长可能超过 CPU 1000倍,这个定律被戏称为黄氏定律(Jensen'Law)。
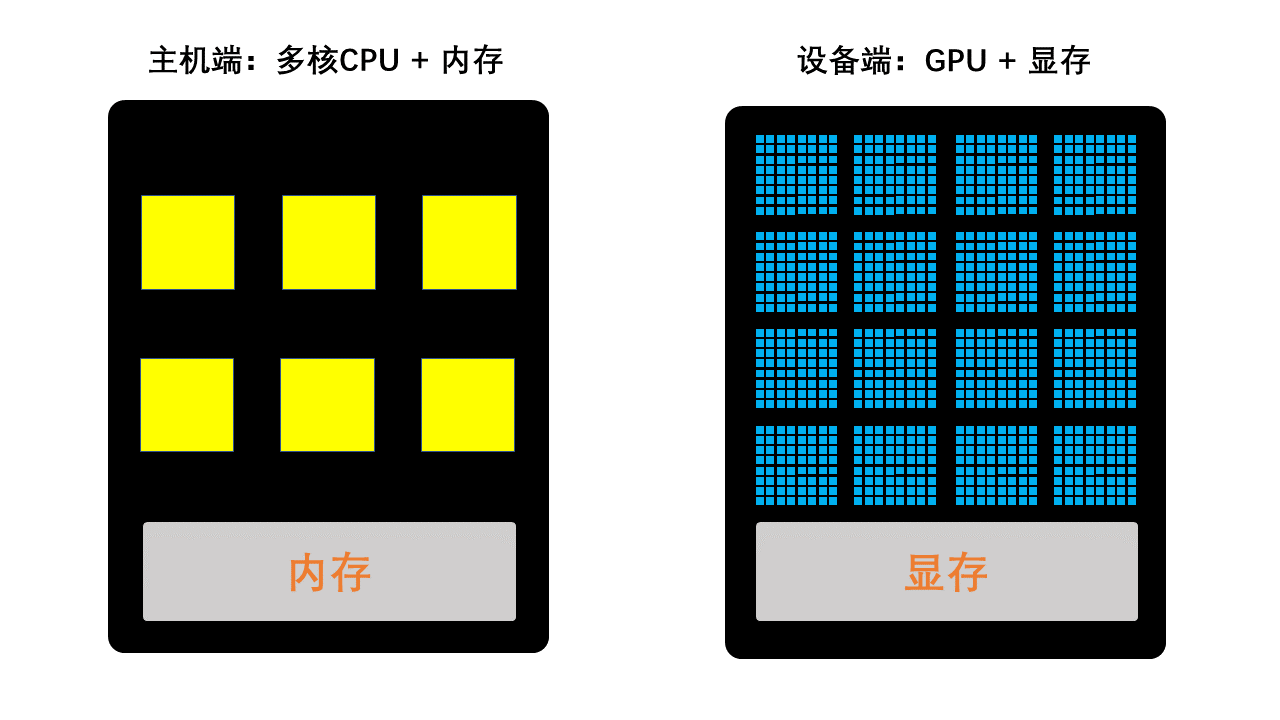
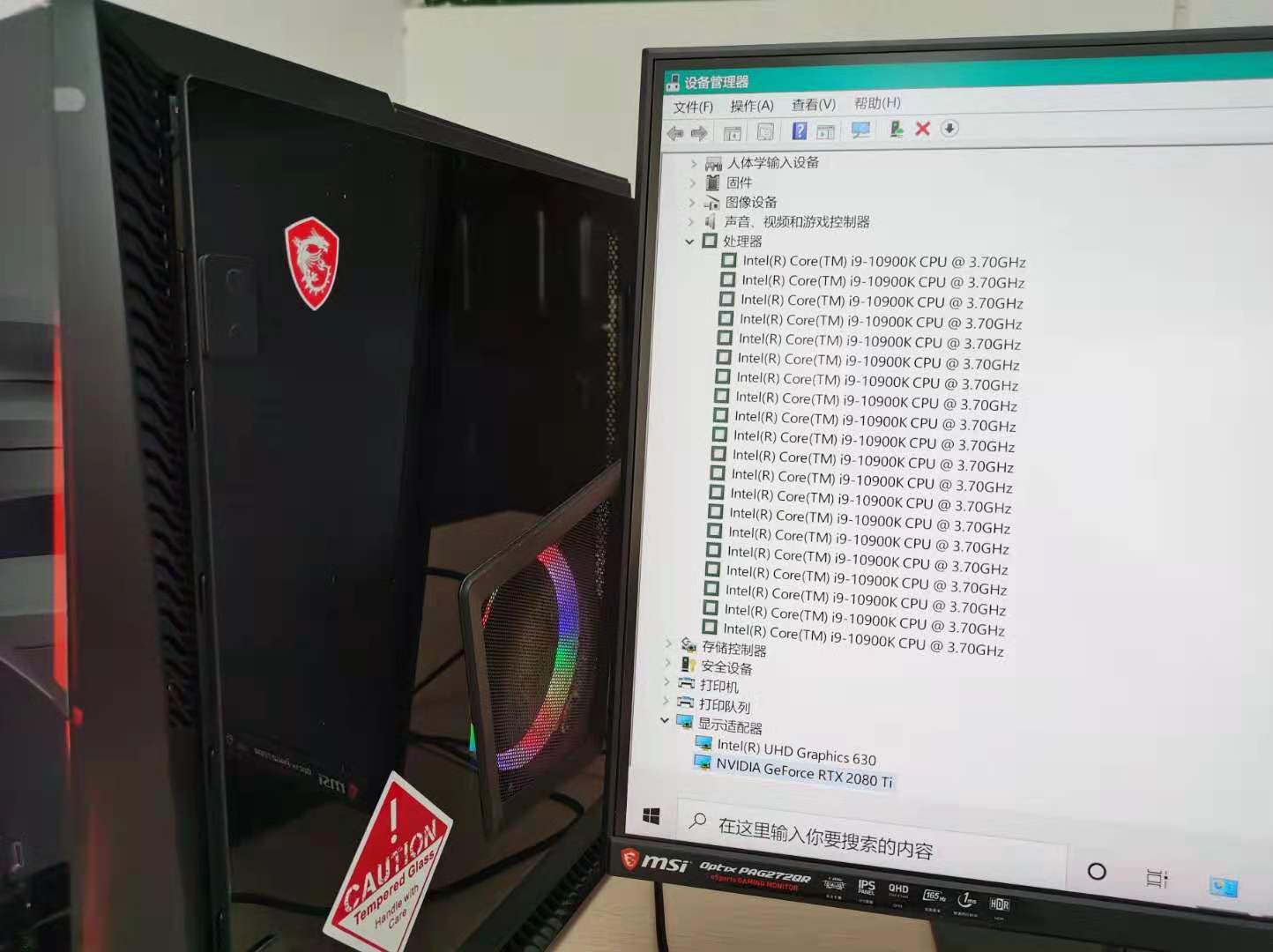
消费级个人电脑¶
| 参数 | GPU: NVidia RTX 2080 Ti | CPU:Intel Core i9-10900K |
|---|---|---|
| 计算核心 | 68 SP (4352 cuda cores) | 10核(20 超线程) |
| 时钟频率 | 1.350 GHz | 3.7 GHz |
| 超频频率 | 1.635 GHz | 5.2 GHz |
SP:Streaming Processor (流处理器,又称 Computing Unit)
计算能力峰值与内存(显存)数据读取速度对比¶
GFLOPS:Gigabyte Floating Operations Per Second
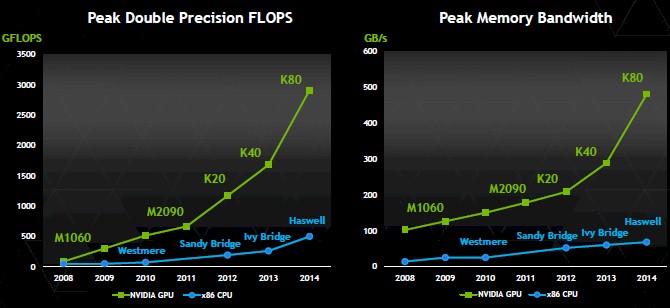
- 单精度浮点数计算: 5.6 Tflops (Tesla K80) vs ~700 Gflops (Intel Xeon E5 server CPUs)
- 双精度浮点数计算:3 Tflops (Tesla K80)
- GPU 显存读写速度(带宽)远大于 CPU
GPU 架构:显存的几种形态¶
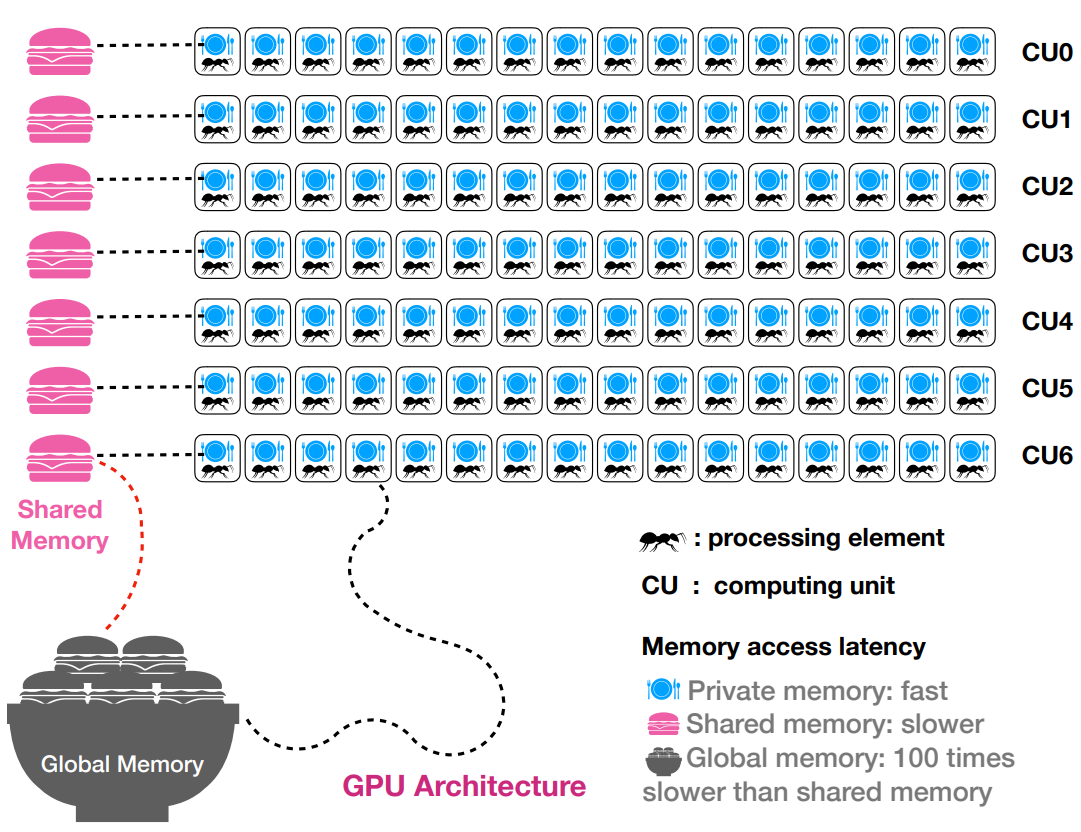
GPU 并行计算时要尽量减少主机端内存到设备端显存的数据传输,比如,对于 ATI Radeon™ HD 5870 GPU,
- 从内存到显存(Global Memory)的数据传输要通过PCI Bus,其带宽为 2.4 GB/S,非常慢
- 从 Global Memory 到 Processing Element 的传输带宽为 118 – 169 GB/s
最好的解决方案是在最开始的时候将数据从内存传到显存,在 GPU 上完成所有计算之后,再将数据从 Global Memory 传回内存。
在 GPU 内部,不同的显存类型也有不同的速度和延迟,
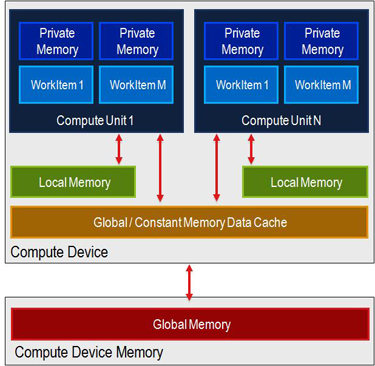
Global memory: GPU side, ~10 GB, speed 100 − 300 GB/s, latency 400 clock cycles.
- 显存中的 Global Memory 最大,几个 GB 到几十个 GB都有,数据传输速度为几百 GB/S, 但是读取有延迟,约 400 个时钟周期
- 400 个时钟周期约等于 400 个加法或100个乘法,或 20-40 个开根号运算
- 所以很多时候宁肯重复计算,也不要多次读写 Global Memory
- 另外,对于一个 workgroup (即 32 或 64 个线程),可以多分配一点数据处理任务,通过(warp switching)掩盖读取延迟
- 相比 Share Memory 和 Private memory,Global Memory 最慢
Shared Memory(Local Memory): 共享显存
- Shared Memory 很小,每个 Computing Unit (CU) 共享一个,大约 32-64 KB
- Shared Memory 读取的速度比 Global Memory 快,延迟小,约 1-40 个时钟周期
- 如果同一个 workgroup 中线程共享数据,可以使用 shared memory
举例:1 维 5 点差分,此时第 i 个格子上的值会在计算(i-2, i-1, i, i+1, i+2)格子上的差分时重复使用 5 次。
Constant Memory:被所有线程共享
- Shared by all PE on GPU.
- 速度在 global memory 和 shared memory 之间
Private memory: on PE, 16-64K per CU.
- Private memory 又称寄存器
- 如果一个数据被单个 workitem 重复利用多次,可放在 Private Memory 中
GPU并行计算的几种方法¶
- Cuda/OpenCL
- OpenACC
- PyOpenCL
- Tensorflow/Pytorch/JAX/Numba
Cuda/OpenCL¶
Cuda 和 OpenCL 属于比较底层的 GPU 并行编程语言,定制性非常强,可以实现最大程度的加速。
Cuda:Nvida 公司专用,只能应用于英伟达(Nvidia)显卡上的 GPU 并行加速,不能应用于CPU加速或其他品牌的GPU/FGPA 加速
OpenCL:开放的异构计算设备并行编程语言,可以应用于 CPU 以及不同品牌显卡上的加速。
这两种语言都包含主机端 host side 代码和设备端 device side 代码。
host side 主要是程序输入输出以及用户控制部分,可以是 C 语言,fortran语言或者 Python 语言
device side 则是程序中计算量很大的代码部分,需要使用 Cuda/OpenCL 定制的 kernel,使用这些 kernel 加速计算。
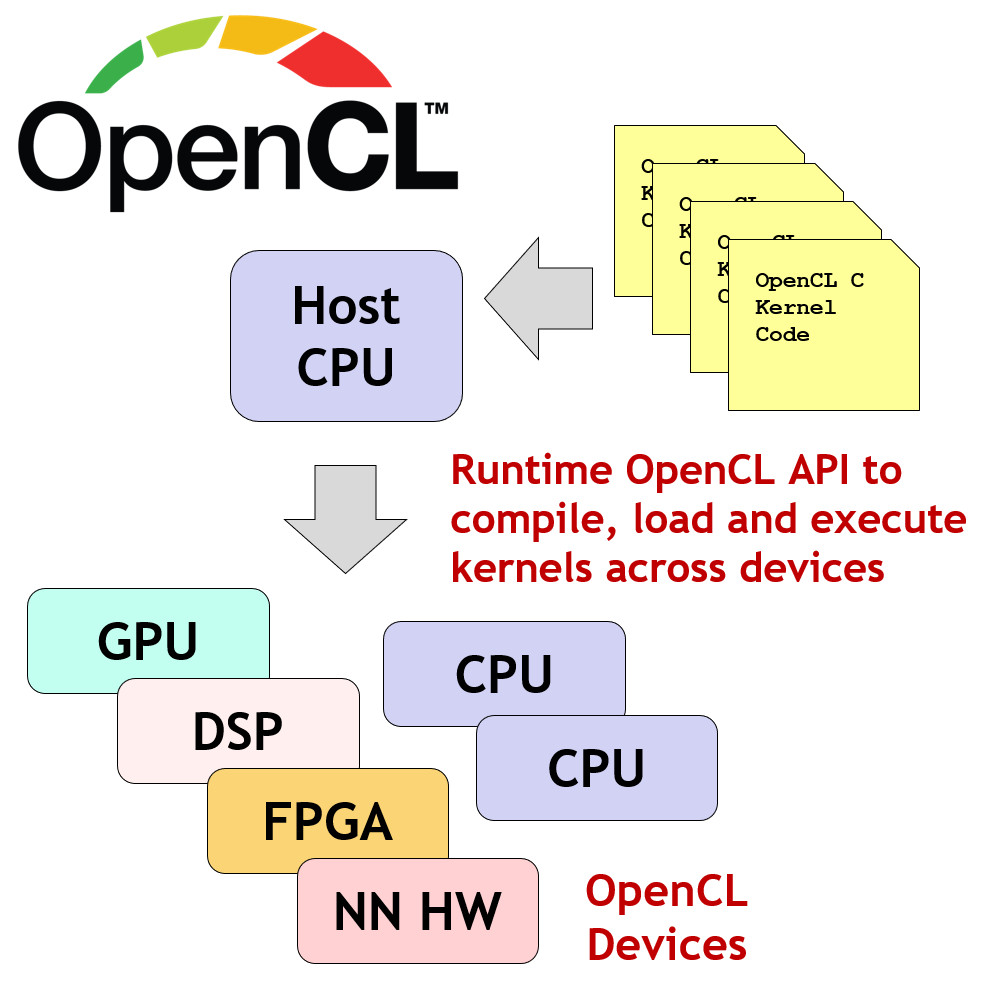
看一下 openCL 的官方描述:
OpenCL is a programming framework and runtime that enables a programmer to create small programs, called kernel programs (or kernels), that can be compiled and executed, in parallel, across any processors in a system. The processors can be any mix of different types, including CPUs, GPUs, DSPs, FPGAs or Tensor Processors - which is why OpenCL is often called a solution for heterogeneous parallel programming.
OpenCL 是一个编程框架和运行时间库,帮助程序员编写小的核心程序(kernels)。kernels 可以在系统中多个处理器上并行的编译、执行。处理器可以是 CPU,GPU,DSP,FPGA 或者 Tensor Processors。这也是为何 OpenCL 被称为“异构”并行编程解决方案。OpenCL 有两层 API (应用程序接口):
- 第一层:平台层 API (Platform Layer API), 主要帮助 host side 发现有多少可用的计算设备并初始化。
- 第二层:运行时间 API (Runtime API),主要帮助在特定的计算设备上编译 kernel,执行计算并收集结果。
OpenCL 中,
- kernel 是基本的执行单位,在 .cl 文件中以 __kernel 标记的函数都是 kernel 函数。
- 多个 kernel 的集合称为一个 program, 收集在同一个 *.cl 文件中
- 一个大的程序可以有多个 .cl 文件,编译时可同时得到多个 program
- 命令序列 command queue 是一个管道, 可以把编译好的 kernel 以及数据发送到设备(Device),并收集计算结果
- 调用 enqueue 函数,可以将命令发送到命令序列,同步(等待执行结果后继续运行)或异步(提交任务后继续运行,不等待执行结果)执行
- 所有上面这些需要在一个上下文环境(Context)中操作
下面这张图展示了具体的 OpenCL 并行程序执行过程,
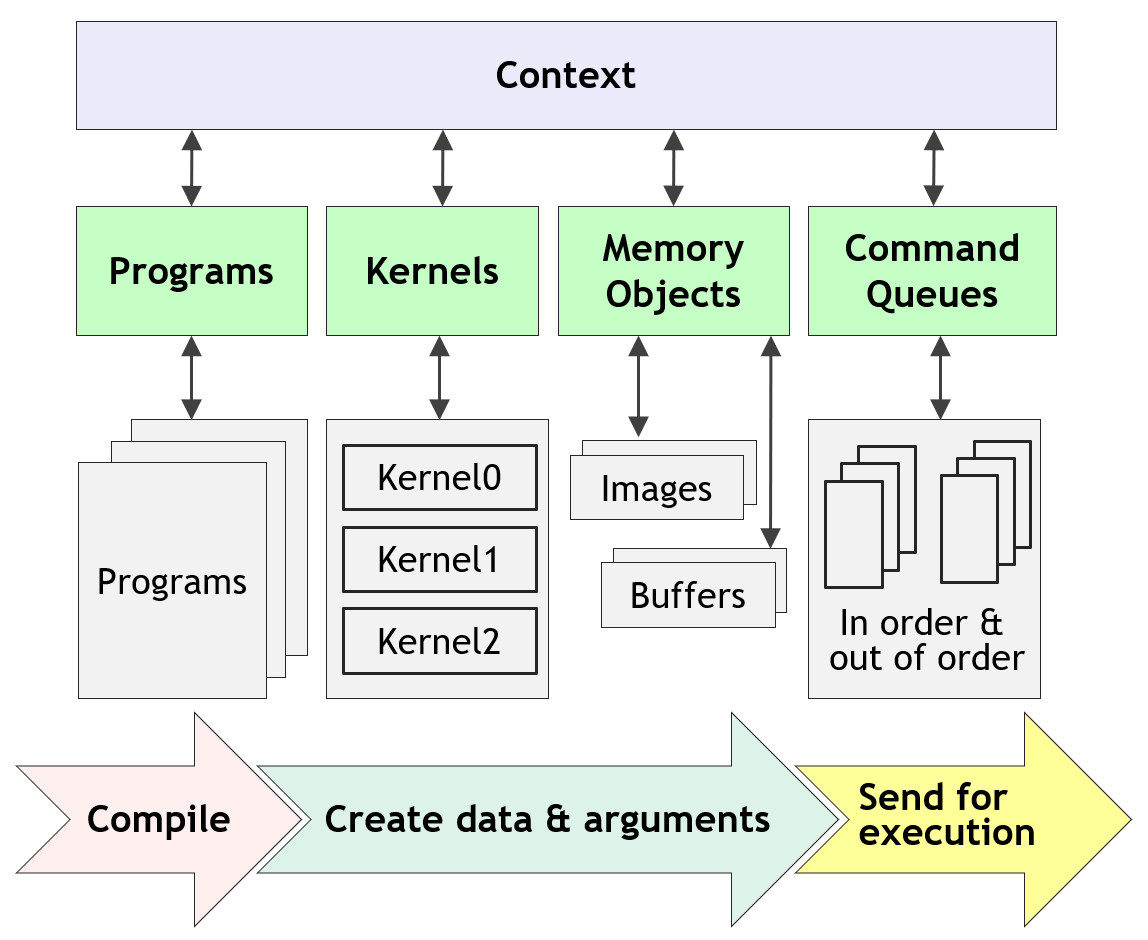
一个 OpenCL 程序的完整执行过程为,
- 查询可用的 OpenCL 平台(platform) 和设备 (devices)
- 创建一个上下文环境 Context, 指定要使用的平台和计算设备
- 创建、编译包含多个 kernels 的 Program (.cl 结尾的文件),选择需要执行的 kernels(相当于函数)
- 为 kernels 创建需要操作的内存(即准备数据)
- 创建命令管道 command queue
- enqueue 数据传输命令到命令管道,将数据从内存拷贝到显存
- enqueue kernels 执行命令到命令管道
- enqueue 数据传输命令到命令管道,将数据从显存拷贝到内存
PyOpenCL¶
PyOpenCL 语言使用 Python 编写 host side 代码,控制程序的主要运行逻辑, 实现数据在内存和显存之间的传递。
使用 OpenCL(C99) 编写 device side 代码(kernels), 运行程序中需要大量计算的代码块。
安装: pip install pyopencl
细节知识参考 Pyopencl 库的官方网站
下面这段代码是 PyOpenCL 官网的示例代码,可以在 Jupyter Notebook 中顺利运行。这段代码完整演示了 GPU 并行编程的过程:
- CPU side 数据的生成
- CPU (np.array) 与 GPU (cl.Buffer) 之间数据的传输
- kernel 程序的编写
- 计算结果的提取 cl.enqueue_copy()
import numpy as np
import pyopencl as cl
a_np = np.random.rand(50000).astype(np.float32)
b_np = np.random.rand(50000).astype(np.float32)
#ctx = cl.create_some_context()
ctx = cl.create_some_context(interactive=True)
queue = cl.CommandQueue(ctx)
mf = cl.mem_flags
a_g = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=a_np)
b_g = cl.Buffer(ctx, mf.READ_ONLY | mf.COPY_HOST_PTR, hostbuf=b_np)
prg = cl.Program(ctx, """
__kernel void sum(
__global const float *a_g, __global const float *b_g, __global float *res_g)
{
int gid = get_global_id(0);
res_g[gid] = a_g[gid] + b_g[gid];
}
""").build()
res_g = cl.Buffer(ctx, mf.WRITE_ONLY, a_np.nbytes)
knl = prg.sum # Use this Kernel object for repeated calls
knl(queue, a_np.shape, None, a_g, b_g, res_g)
res_np = np.empty_like(a_np)
cl.enqueue_copy(queue, res_np, res_g)
# Check on CPU with Numpy:
print(res_np - (a_np + b_np))
print(np.linalg.norm(res_np - (a_np + b_np)))
assert np.allclose(res_np, a_np + b_np)
OpenCL 语言中 kernel 的编写¶
kernel 代码一般存放在单独的文件中,编译时读入。
为 PyOpenCL 编写的设备端 kernel 也可以直接被主机端的 C++ 代码调用。
上面例子展示的是两个大数组 a[50000] 和 b[50000] 的逐元素相加操作。
kernel 代码如下,并未看到有 for 循环,这是因为 GPU 并行编程时可以让一个线程执行一个数组元素的相加。
每个线程通过 get_global_id(0) 可以得到自己的线程 id,然后仅仅对一个数据执行操作。
__kernel void sum( // __kernel 说明这段程序是 kernel 函数
__global const float *a_g, // __global 说明数组 a_g 存放在全局显存中
__global const float *b_g, // __global 说明数组 b_g 存放在全局显存中
__global float *res_g) // __global 说明数组 res_g 存放在全局显存中
{
int gid = get_global_id(0); // 得到当前线程(Processing Element)的 gid
res_g[gid] = a_g[gid] + b_g[gid];// 使用当前线程操作数组中第 gid 个元素
}
对应的 C++ 代码如下,可以看到其中有一个 for 循环,串行相加,
void vectorAdd(float *a, float *b, float *c, int N) {
for (int i = 0; i < N ; i++){
c[i] = a[i] + b[i];
}
}
如何线程的 id 与数据的 id 对应起来呢? 这需要在主机端指定工人数量,即 how many work-items。
prg.sum(queue, a_np.shape, None, a_g, b_g, res_g)
program 中的 kernel 函数 sum() 调用时多出来 3 个参数,分别是
- 命令通道 command queue
- 总共需要多少个线程,如何排兵布阵(1维,2维还是3维,每一个维度放置多少个线程)
- 每个工作组 work group 需要多少个线程(应被每个维度总线程数整除)
这里 a_np.shape 指定了工人总数与 a_np 数组中数据的个数一致。
None 那里指定不需要分工作组(work-group),因为没有数据需要不同线程共享。
比如,在 CLVisc 代码中,将 BSZ 个工人放置在同一个工作组里,实现 5点差分时的数据共享。
prg.visc_src_alongx(self.queue, # 命令序列
(BSZ, NY, NZ), # 设置总的工人数量
(BSZ, 1, 1), # 设置每个小组中工人数量
self.d_IS_src, # 下面的全是参数
self.d_udx ,
self.d_pi[step],
self.ideal.d_ev[step],
self.eos_table,
self.ideal.tau).wait()
从硬盘load .cl文件并编译的例子代码:
很多时候可以根据程序配置,动态设置 kernel 的预编译参数。
如果想在 .cl 文件中加 #define NX 101 这样的 C 语言预编译指令,可以定义,¶
gpu_defines = []
gpu_defines.append('-D {key}={value}'.format(key='NX', value=101))
如果仅仅想声明一件事情,比如 USE_SINGLE_PRECISION,可以定义¶
gpu_defines.append('-D USE_SINGLE_PRECISION')
如果 .cl 以及与之相关的 .h 文件都统一放在 kernels/ 文件夹下,可以加编译指令¶
cwd, cwf = os.path.split(__file__)
gpu_defines.append('-I '+os.path.join(cwd, 'kernel'))
在编译 Program 的时候,将 gpu_defines 作为编译参数,
with open(os.path.join(cwd, 'kernel', 'kernel_ideal.cl'), 'r') as f:
prg_src = f.read()
self.kernel_ideal = cl.Program(self.ctx, prg_src).build(
options=' '.join(gpu_defines))
GPU 并行编程中的坑 (以 PyOpenCL 为例)¶
同步,如果需要一个 kernel 执行完,再运行其他kernel,或者需要数据拷贝完(cl.enqueue_copy), 一定要在后面加 .wait()¶
self.kernel_reduction.reduction_stage1(self.queue, (256*64,), (256,),
self.d_ev[1], self.d_submax, np.int32(self.size) ).wait()
cl.enqueue_copy(self.queue, self.submax, self.d_submax).wait()
float3 数据类型¶
float3 数据类型在 opencl 中存储为 float4,有时会引起奇怪的错误;尽量不要使用。
host side 调用 kernel 函数时,注意常数参数¶
比如,上面 reduction_state1 kernel 函数,最后一个参数是常数,需要用强制数据类型转换,使其与 kernel 定义时数据类型一致。
- 此处使用 np.int32(self.size) 将其强制转换为 int32 类型
设备端 kernel 编程可能遇到的问题
- 尽量避免使用多个 if else 判断语句
- 设置了 Barrier,但有些线程因为 if else 语句,运行不到 Barrier,导致 GPU 卡死
kernel 编程时,除了 global, 还有 local, __constant 类型指示符,表示 GPU 上数据存在于不同的地址。
除了 get_global_id(0), 还有 get_global_id(1), get_global_id(2) 表示不同的方向,举例,
__kernel void total_energy_and_entropy(
__global real * d_ed_lab,
__global real * d_s_lab,
__global real4 * d_ev,
read_only image2d_t eos_table,
const real tau) {
int I = get_global_id(0);
int J = get_global_id(1);
int K = get_global_id(2);
int idx = I * NY * NZ + J * NZ + K;
...
}
总计算量为 $(n_x, n_y, n_z)$ 的 3 维计算任务,可以分配到 2 维分布的 $(nx, ny)$ 个线程上,这样每个线程可以处理 $n_z$ 个数组,
// each thread calc one slice of initial energy density with fixed
// (x, y) and varying eta_s
__kernel void glauber_ini(__global real4 * d_ev1 )
{
int i = get_global_id(0);
int j = get_global_id(1);
real x = (i - NX/2)*DX;
real y = (j - NY/2)*DY;
real Tcent = thickness(0.0f, 0.0f);
real ed_central = ed_transverse(Tcent, Tcent);
real kFactor = Edmax / ed_central;
real b = ImpactParameter;
real Ta = thickness(x-0.5f*b, y);
real Tb = thickness(x+0.5f*b, y);
real edxy = kFactor*ed_transverse(Ta, Tb);
real etas0_ = etas0(Ta, Tb);
for ( int k = 0; k < NZ; k++ ) {
real etas = (k - NZ/2)*DZ;
real heta = weight_along_eta(etas, etas0_);
d_ev1[i*NY*NZ + j*NZ + k] = (real4)(edxy*heta, 0.0f, 0.0f, 0.0f);
}
}
如果工人被放在不同的工作组 work-group, 在 kernel 里还可以通过 get_group_id(0) 和 get_local_id(0) 来 获取当前工人沿第 0 个方向,处在第几个工作组的第几个工位。
另外,有 get_global_size(0) 来获得第 0 个方向上总共分配了多少个工人。
get_local_size(0) 来获得一个工作组 work-group 中第 0 个方向上总共分配了工位。
如果一个维度的线程全被放在一个 work group 中,则可使用共享内存(local memory),
// output: d_Src; all the others are input
__kernel void kt_src_alongx(
__global real4 * d_Src,
__global real4 * d_ev,
read_only image2d_t eos_table,
const real tau) {
int J = get_global_id(1);
int K = get_global_id(2);
__local real4 ev[NX+4];
...
Cuda 的 kernel 与 OpenCL 的 kernel 只有微小的命名上的差别。
比如,OpenCL 中 kernel 关键词在 Cuda 中为 global,
OpenCL 中的内建函数 get_global_id(0) 对应 Cuda 中的内建变量 threadIdx.x。
所以,一般学会了一种 Kernel 的编写,可以很容易扩展到另一种 kernel。
PyOpenCL 中 array 的使用¶
# 实际编写时,也可使用 pyopencl 中定义好的一些辅助方法,
# 比如 A = array.Array(cq, shape, dtype) 产生一个 Array
# 用 array.sum(A).get() 完成 GPU 上的求和,并把结果传输回 CPU
from pyopencl import array
A = array.Array(queue, a_np.shape, a_np.dtype)
cl.enqueue_copy(queue, A.data, a_np)
array.sum(A).get()
新的 GPU 并行编程范式¶
现在主流的深度学习库都实现了底层的 GPU 并行编程,用户接口仍然是高级语言,比如 Python,
如果涉及对大量数组的操作,可以直接在 Python 中调用这些库,使用 GPU 的并行加速能力, 而不用忍受复杂的底层 GPU kernel 的编写。
这样的库主要包括,
- tensorflow
- pytorch
- mxnet
- jax (需要安装 jax, jaxlib, 目前 jaxlib 只支持 linux/mac)
- numba
from numba import cuda
print(cuda.gpus)
from numba import cuda
def cpu_print(N):
for i in range(0, N):
print(i)
@cuda.jit
def gpu_print(N):
idx = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x
print(idx)
def main():
print("gpu print:")
gpu_print[2, 4](8)
cuda.synchronize()
#print("cpu print:")
#cpu_print(8)
main()
MPI 并行:多节点通信¶
如果计算资源是多个计算节点的超级计算机集群,需要用到多个节点之间的通信及数据传输。
此时需要使用 MPI (Message Passing Interface) 库。
Windows 下,推荐使用微软的 MPI 库:Microsoft MPI v10.0
Linux 或 Mac 下,推荐安装 OpenMPI
安装后,
- Windows 操作系统下,在 terminal 里运行:mpiexec 测试安装是否成功
- Linux 操作系统下,在 terminal 里运行:mpirun 测试安装是否成功
接下来使用 Python 库 mpi4py 来与 mpiexec 或 mpirun 沟通,在多个节点上运行并行程序。
安装方法:pip install mpi4py
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
print(rank)
# with open() 将引号中的代码写入 test1.py
with open("test1.py", "w") as fout:
fout.write('''
from mpi4py import MPI
import numpy
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
# passing MPI datatypes explicitly
if rank == 0:
data = numpy.arange(1000, dtype='i')
comm.Send([data, MPI.INT], dest=1, tag=77)
elif rank == 1:
data = numpy.empty(1000, dtype='i')
comm.Recv([data, MPI.INT], source=0, tag=77)
print("I am rank 1, received %s,%s,%s ..."%(data[0], data[1], data[2]))
# automatic MPI datatype discovery
if rank == 0:
data = numpy.arange(100, dtype=numpy.float64)
comm.Send(data, dest=1, tag=13)
elif rank == 1:
data = numpy.empty(100, dtype=numpy.float64)
comm.Recv(data, source=0, tag=13)
print("I am rank 1, received %s,%s,%s ..."%(data[0], data[1], data[2])))
''')
在 Anaconda Prompt 命令行运行 mpiexec -n 4 python test1.py,可以看到打印出两句话,
I am rank 1, received 0,1,2 ...
I am rank 1, received 0.0,1.0,2.0 ...上面这串代码展示了 MPI 编程的基本过程,
- 创建世界通信域 comm = MPI.COMM_WORLD
- mpiexec -n 4 说明要使用 4 个节点(CPU)进行并行计算
- 每个节点上都会运行 rank = comm.Get_rank(),得到当前节点的id,即 rank
- 在 rank=0 的节点上准备数据,然后发送到其他节点(比如,dest=1,即 rank=1 的节点)
- 在其他节点上接收数据,收到后开始对数据进行操作,计算完成后,将数据传递到 rank=0 或其他 rank 的节点
- 所有节点计算任务完成后,在总节点(比如 rank=0)上进行归纳 (Reduce)
更全面的 mpi4py 文档在 这里 寻找。
单节点并行(共享内存):OpenMPI¶
如果计算资源只有一个节点,但此节点上有多个 CPU,那么可以使用 OpenMP 进行共享内存多线程并行编程。
OpenMPI 是一组编译指令集,加在 C++ 代码里,编译的时候自动将相应的代码块并行化。
在 C/C++ 代码中,以 # 开头的行是“预处理”指令,在编译的时候编译器会将代码进行翻译。
比如,OpenMP 对一个 for 循环进行并行化的代码如下,
int i, a[nmax];
#pragma omp parallel for
for (i=0; i< nmax; i++) {
int j = 5 + 2*i;
a[i] = compute(j);
}
OpenMP 的预处理指令是这一行, #pragma omp parallel for
使用 OpenMP 可以比较方便的将已有的 C/C++ 代码转化为共享内存的多线程并行代码。
Python 中自带 multiprocessing 模块,可以进行类似 OpenMP 的并行。
import multiprocessing as mp
print("处理器个数: ", mp.cpu_count())
将下面的代码粘贴到 test2.py, 并在 Anaconda Prompt 中运行 python test2.py
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))
这段代码表示开启 5 个线程的线程池 Pool(5),然后平均分配 [1, 2, 3] 这个数组中的数据,在不同的线程上运行 f(x) 函数。
注意:Jupyter notebook 直接运行上述代码会出现问题,即便删掉 name = 'main' 那行。
此过程涉及大量的代码修改,尤其是编写可以在 GPU 上运行的 kernel,需要对硬件、Cuda或OpenCL语言有较深的理解。
单节点并行:OpenACC¶
OpenACC 与 OpenMP 相似,但可以通过预编译指令实现 GPU 并行编程。
#pragma acc data copy(A, Anew)
while ( error > tol && iter < iter_max ) {
error = 0.f;
#pragma omp parallel for shared(m, n, Anew, A)
#pragma acc kernels
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
Anew[j][i] = 0.25f * (A[j][i+1] + A[j][i-1] + A[j-1][i] + A[j+1][i]);
error = fmaxf(error, fabsf(Anew[j][i]-A[j][i]));
}
}
#pragma omp parallel for shared(m, n, Anew, A)
#pragma acc kernels
for( int j = 1; j < n-1; j++) {
for( int i = 1; i < m-1; i++ ) {
A[j][i] = Anew[j][i];
}
}
if(iter % 100 == 0) printf("%5d, %0.6fn", iter, error);
iter++;
}
与 openmp 相比,多了下面两句:
#pragma acc data copy(A, Anew)这句出现在 while 循环之外。它表示循环之前把数据从内存拷贝到显存,循环结束后把数据再从显存拷贝到内存。#pragma acc kernels这句表示接下来的循环要使用“加速器”,比如 GPU 的 kernel 进行加速。
总结¶
- GPU 并行编程可以带来 "Parallel Supremacy"
- 使用 GPU 并行编程,消费级个人电脑即可提供强大的并行计算资源
- GPU 并行编程语言最常用的是:Cuda 与 OpenCL
- 新的编程范式下,可以使用深度学习库,掩藏了 GPU 并行编程的细节